導出を用いた機械学習
正データ学習
クラスタリングなどの正データからの機械学習の困難さを計算論的に解析することは, 機械学習の基本的な問題であり,後述するように数学基礎論や代数学とも密接に関連します. 木構造データを対象として,導出を用いることにより,学習可能なクラスとして新たなものを提示することに成功しました.
属性としての導出
文脈自由文法などの生成文法では,文法から文字列を生成する過程が導出(精密化)です. 文法を一つ固定し,データはその文法が生成する形式言語の要素である文字列としますと, 各データに対して少なくとも一つそのデータを生成した導出が存在します. このことは,導出がデータの属性であることを示し,導出を用いて機械学習手法を適用することが可能となります. RNAの分類問題に対しては,各データを生成する導出(の同値類)を列挙するアルゴリズムを構築した上で, 機械学習手法としてクラスタリング手法を利用しています.
内包カーネル [1-1]
属性として導出を用いることにより,構造データにサポートベクトルマシンを適用するための新たなカーネル関数の 一族を「内包カーネル」として定式化しました. 一階述語論理の原子論理式や文脈自由文法を利用した内包カーネルを計算の効率化を含めて設計しています. 構造データを扱うカーネル関数の一族としては合成積 カーネルが有名であるが, 内包カーネルはそれとは対照的な発想に基づいています.RNAの分類問題用の内包カーネルは, 合成積カーネルと比肩して遜色ない性能を出しています.
文字列パターンと精密化 [1-5]
計算論的学習理論における極限同定の枠組みにおいて,広く研究されているモデルの1つに文字列パターンがあります. 文字列パターンは定数文字と変数から構成される1つの文字列で,文字列パターン中の変数は代入によって 別のパターンへと置き換えられます.ある文字列パターンの変数を全て文字列に置き換えて構成される集合をパターン言語と呼びます. 過去の研究においては,文字列に置き換えるために代入の全ての可能性を考えていましたが,新しい枠組みとして代入を制限し, それを精密化と見なすことで,文字列パターンと精密化によるパターン言語の改装を作り, それを文字列データのデータ生成モデルと見なすことができます.このデータ生成モデルから文字列上の確率モデルを作り, それを推定する問題を解いたのが[1-5]の論文です.その後,より精密化自体に着目した研究へと進んでいます.
関係する論文
- [1-1] Sankoh, H., Doi, K., Yamamoto, A. : An Intentional Kernel Function for RNA Classification, Proceedings of the 10th International Conference on Discovery Science, (Lecture Notes in Artificial Intelligence 4755), 281-285, 2007.
- [1-2] Viet Anh Nguyen, Akihiro Yamamoto : Incremental Mining of Closed Frequent Subtrees, Proceedings of the 12th International Conference on Discovery Science, (Lecture Notes in Artificial Intelligence 6332), 356-370, 2010.
- [1-3] Ouchi, S., Yamamoto, A. : Learning from Positive Data based on the MINL Strategy with Refinement Operators, Revised Selected Papers of LLLL 2009 (Lecture Notes in Artificial Intelligence 6284), 345-357, 2010.
- [1-4] Yudai Kawai, Mahito Sugiyama, Akihiro Yamamoto : Mining RNA Families with Structure Histograms, The 5th International Workshop on Data-Mining and Statistical Science (DMSS2011), 2011.
- [1-5] Otaki, K., Yamamoto, A.:Estimation of Generating Processes of Strings Represented with Patterns and Refinements, The 11th International Conference on Grammatical Inference (ICGI2012), 2012.
木構造データに対する機械学習,知識発見,文法圧縮
木構造データからなるデータベースに対しては,導出以外の性質を利用した機械学習手法を開発しています.
木構造データの文法圧縮と知識発見 [2-1]
文法圧縮は,生成文法を利用したデータ圧縮手法であり,データ内の重複している部分を生成文法に 置き替えながら圧縮を行います.木構造データに対する文法圧縮は,オーバラップの処理が必要ない上に, 重複している部分を見つけることはデータマイニングの一種とみなすことができます. そこで,木構造データに対して文法圧縮を積極的に利用したデータマイニング・アルゴリズムを開発しました[2-1].
木構造データからの知識発見 [2-2, 2-3, 2-4, 2-5]
ある制約を満たすパターンだけをデータマイニングの結果として出力するアルゴリズムを研究しています. 木構造に対する制約として自然な部分木構造を用いて,ユーザの意図を制約の形で課すことができるアルゴリズムを開発しました[2-2],[2-4]. またデータが徐々に変化する状況において,既存の計算結果を再利用することで, できるだけ再計算のコストが少ないマイニングアルゴリズムを開発しました[2-3]. また本研究室で広く利用されている形式概念分析を無向グラフを対象とした機械学習アルゴリズムへと応用し, 無向グラフによって構成される概念束を定義し,概念束を用いたマイニングアルゴリズムを開発しました[2-5].
関係する論文
- [2-1] Murakami, S., Doi, K., Yamamoto, A. : Finding Frequent Patterns from Compressed Tree-Structured Data, Proceedings of the 11th International Conference on Discovery Science, (Lecture Notes in Artificial Intelligence 5255), 284-295, 2008.
- [2-2] Viet Anh Nguyen, Akihiro Yamamoto : Incremental Mining of Closed Frequent Subtrees, Proceedings of the 12th International Conference on Discovery Science, (Lecture Notes in Artificial Intelligence 6332), 356-370, 2010.
- [2-3] Anh, N. V., Yamamoto, A.: Mining of Closed Frequent Subtrees From Frequently Updated Databases, Intelligent Data Analysis, 16(6), 2012.
- [2-4] Anh, N. V., Yamamoto, A.: Efficient Mining of Closed Tree Patterns From Large Tree Databases With Subtree Constraint, International Journal on Artificial Intelligence Tools, 2012.
- [2-5] Anh, N. V., Yamamoto, A.: Learning From Graph Data by Putting Graphs on The Lattice, Expert Systems With Applications, 2012.
実数の離散化による機械学習
実数のコード化を利用した学習方式 [3-1, 3-2]
学習アルゴリズムに実数のコード化を取り込むことで,効果的な学習手法を提案しました. コード化という帰納的な手続きに基づいて数値データを離散化することで, 連続的な数値データを位相や距離といった「構造」が与えられた離散データとして扱います. これによって,データ間の類似度計算や,それに基づく分類,クラスタリングなどが高速かつ頑健に実行できます. 具体的には,コード化の過程に潜むフラクタル性に着目することで機械学習における2値クラス分類問題をユークリッド空間上の 閉集合の学習として定式化し(図3-1), クラス分類問題の限界を計算論的な側面から明らかにしました [3-1]. また,データ集合間の類似度を「符号化ダイバージェンス」として定式化し(図3-2), 最近傍法に基づく分類によってその有効性を確認しました [3-2].
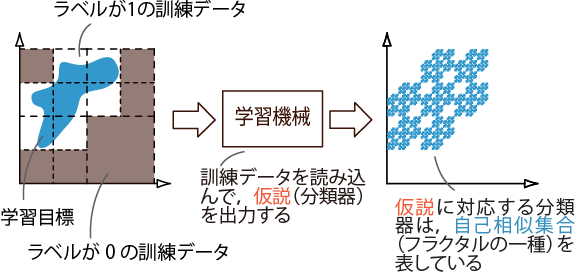
図3-1.クラス分類の計算論的な学習方式.学習機械は訓練データを受け取り,そこから仮説を出力する.各仮説は分類器に対応しており,自己相似集合を表している.このプロセスを繰り返して,仮説の精度を良くしていく.

図3-2.符号化ダイバージェンスの計算.左の例では,青いデータ集合と赤いデータ集合の間の符号化ダイバージェンスは2/10 + 2/10 = 0.4(2はコードのビット数,10はデータ数)となり,右の例では26/10 + 26/10 = 5.2となる.
木構造を利用した高速な類似度計算手法 [3-5]
符号化ダイバージェンスの性質を利用して,データを逐次的に読みながら木構造として管理し,類似度の計算を高速に行うための手法を開発しました [3-5].
クラスタリングへの応用 [3-3, 3-4, 3-6]
符号化ダイバージェンスを計算するために実数データを符号化するときの計算手法に着目し, 新規のクラスタリング手法などを開発しており [3-3], 準備実験では任意形状を発見するクラスタリング手法として世界最速を記録しました. より詳細に新規のクラスタリング手法を検証・実験した結果は国際会議において発表しました [3-4], [3-6]. 著者たちの知る限りにおいて,世界最速の手法となっています.
ガウス関数の高速化に基づいたクラス分類手法 [3-8, 3-9]
ガウス関数を別の関数に畳み込む演算は,信号処理・画像処理においてフィルタなどとして広く利用されています. 本研究ではガウス関数を離散化し,畳み込み積分を累積和によって実現する際に高速に計算する手法を構築しました [3-8]. またその手法を基にして,畳み込みを行った値に基づく高速な二値分類手法を構築し, SVMと比べて遜色のない精度を得られることを確認しました [3-9].
関係する論文
- [3-1] Sugiyama, M., Hirowatari, E., Tsuiki, H., Yamamoto, A.: Learning Figures with the Hausdorff Metric by Fractals, Proceedings of the 21th International Conference on Algorithmic Learning Theory (ALT 2010), Lecture Notes in Artificial Intelligence 6331, 315-329, 2010.
- [3-2] Sugiyama, M., Yamamoto, A.: The Coding Divergence for Measuring the Complexity of Separating Two Sets, Proceedings of the 2nd Asian Conference on Machine Learning (ACML2010), JMLR: Workshop and Conference Proceedings 13, 127-143, 2010.
- [3-3] Sugiyama, M., Yamamoto, A. : Fast Clustering Based on the Gray-Code (extended abstract), In Proceedings of 7th Workshop on Learning with Logics and Logics for Learning (LLLL2011), p. 42, 2011.
- [3-4] Sugiyama, M., Yamamoto, A. : The Minimum Code Length for Clustering Using the Gray Code, ECML PKDD 2011 (LNCS 6913), 2011.
- [3-5] Sugiyama, M., Yoshioka, T., Yamamoto, A. : High-throughput Data Stream Classification on Trees, Proceedings of The Second Workshop on Algorithms for Large-Scale Information Processing in Knowledge Discovery (ALSIP 2011), 2011.
- [3-6] Sugiyama, M., Yamamoto, A. : A Fast and Flexible Clustering Algorithm Using Binary Discretization, IEEE ICDM 2011, 2011.
- [3-7] Sugiyama, M., Hirowatari, E., Tsuiki, H., Yamamoto, A. : Learning Figures with the Hausdorff Metric by Fractals―Towards Computable Binary Classification, Machine Learning, 90(1), 91-126, 2013.
- [3-8] Imajo, K.: Fast Gaussian Filtering Algorithm Using Splines. Proceedings of the 21st International Conference on Pattern Recognition (ICPR 2012), 2012.
- [3-9] Imajo, K., Otaki, K., Yamamoto, A.: Binary Classification Using Fast Gaussian Filtering Algorithm, Proceedings of The Third Workshop on Algorithms for Large-Scale Information Processing in Knowledge Discovery (ALSIP 2012), 2012.
形式概念解析の応用 [3-1, 3-2]
データを,対象の集合と属性の集合の二項関係と見なした上で,代数的構造を用いて分析する「形式概念解析」という手法は,仮説の学習,頻出アイテム集合の発見といった機械学習,データマイニングの基本的問題に用いられてきました. 我々の研究室では,近年の多様化の進んだデータから学習やマイニングを行なう際の代数的なアプローチとして,形式概念解析を応用する研究を行っています.
離散値・連続値混在データからの半教師あり学習 [4-1, 4-2]
機械学習に用いられているデータはますます多様化しており,その中でも例えばネットワークの不正侵入検知のためのデータのように, 離散値と連続値が混在しているデータが多く出現しています. しかし,このような離散値・連続値混在データに対する機械学習手法としては,C4.5のような古典的手法しか提案されていません.一方,関係データベースからの機械学習において,データのもつ代数的な性質が鍵となることが明らかとなってきています.そこで,形式概念解析を活用した離散値・連続値混在データのための機械学習手法を開発しました [4-2]. 特に,半教師あり学習と呼ばれている,正解のわかっているデータ,わからないデータを共に用いて未知データの分類規則を学習するという課題に取り組みました. 代数的に「閉じている」性質に着目することで,訓練データから束構造を導出し(図 4-1), その上での極大性を利用することで正解付きデータを有効に使った学習を実現しました.実データを用いた実験により, C4.5のような他の機械学習手法より良い性能が出ることを確認しました.
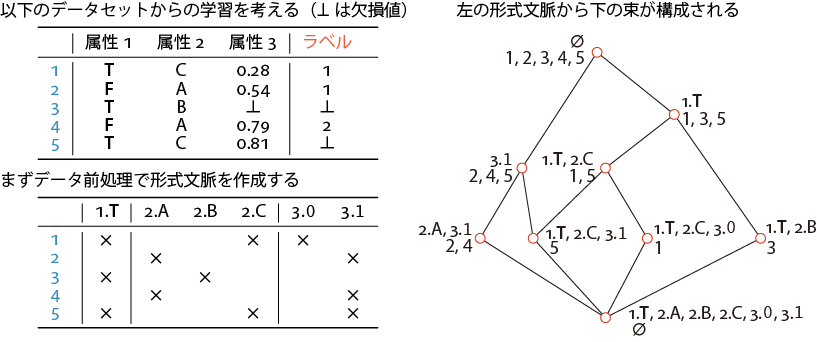
図4-1.形式概念解析による束の構成.ここから分類規則を学習する.
頻繁に更新されるデータからの局所的な特徴選択を用いた怠惰学習 [4-3]
実際のデータベースの多くは,次々と新たなデータが加えられることにより増大していきます.気象データや株価データはもちろん,Webページのコンテンツも時間とともに増加していくデータ集合です.そのようなデータベースからの学習を考える場合,データベースが更新される度に一から学習を行うのではなく,更新された部分についてのみ逐次的に学習を行う怠惰学習という考え方があります.k近傍法に代表されるこのタイプの学習は,未知のデータをクラス分類する際,分類ルールを学習する代わりに,特徴空間上で近傍(クラスの分かっているデータのうち未知データに類似するもの)を探してそれを参考に未知データをクラス分類します.学習に適した特徴空間を獲得することを目的として,特徴選択という前処理がデータに対して行われます.一般に,特徴選択は全てのデータを対象として,それらを分類するために適した特徴空間の獲得を目的としています.しかし,未知データそれぞれについて分類に適した特徴空間が存在すると予想されます.本研究は,形式概念を各未知データに対する特徴選択の結果とそれにより決定される近傍の集合であると見なすことで,怠惰で局所的な特徴選択を行う手法を提案し,実験によりk近傍法より高い精度でクラス分類可能であることを確認しました.
関係する論文
- [4-1] Nguyen, D. A., Doi, K., Yamamoto, A. : Discovering the Structures of Open Source Programs from Their Developer Mailing Lists, Proceedings of the 12th International Conference on Discovery Science, (Lecture Notes in Artificial Intelligence 5808), 227-241, 2009.
- [4-2] Sugiyama, M., Yamamoto, A. : Semi-Supervised Learning for Mixed-Type Data via Formal Concept Analysis, The 19th International Conference on Conceptual Structures (ICCS2011), 2011 (ProceedingsはLecture Notes in Artificial Intelligenceに掲載).
- [4-3] Ikeda, M., Yamamoto, A.: Classification by Selecting Plausible Formal Concepts in a Concept Lattice, Proceedings of Workshop on Formal Concept Analysis meets Information Retrieval (FCAIR2013), 22-35, 2013.
プライバシー保護データマイニング
大量のデータを扱う場合の一つの方法として,データマイニングを分散処理によって行う方法があります.しかし大量のデータを分散して処理する場合や,分散して各地に保存されているデータを対象とした分散処理は,その処理を達成するためにデータベース間での通信や情報の共有が書かせません.そのため,データマイニングを達成する代わりに,各サイト所持している外部へ流出させられない機密性の高い情報が漏洩する可能性が指摘されており,その対策としてプライバシー保護データマイニングという分野の研究が進んでいます. そこで本研究室では頻出パターンマイニングなどの基本的なデータマイニング手法を対象として,分散処理を行う際のデータ構造に注目した研究を行っています.例えば頻出パターンマイニングでは,各サイトが所有するデータをパターンの集合として表現しますが,集合を秘匿するための暗号学的な処理(準同型性暗号)に注目したり ([5-1]),集合をBDDやZDDに代表される木構造として表現する場合において,木構造に注目した上でデータの秘匿性を確保するような偽の情報を追加する処理に注目したりして ([5-2], [5-3]),プライバシー保護データマイニングを研究しています.
関係する論文
- [5-1] Shin-ya Kuno, Koichiro Doi, Akihiro Yamamoto : Frequent Closed Itemset Mining with Privacy Preserving for Distributed Databases, Proceedings of the 10th ICDM Workshop on Privacy Aspects of Data Mining (PADM 2010), 483-490, 2010.
- [5-2] Keisuke Otaki, Akihiro Yamamoto : Preserving Privacy with Dummy Data in Set Operations on Itemsets, Proceedings of The Second Workshop on Algorithms for Large-Scale Information Processing in Knowledge Discovery (ALSIP 2011), 2011.
- [5-3] Keisuke Otaki, Mahito Sugiyama, Akihiro Yamamoto : Privacy Preserving using Dummy Data for Set Operations in Itemset Mining Implemented with ZDDs, IEICE Transactions on Information and System, Vol. E95-D, No. 12, 3017-3025, 2012.
不確実性を持つ論理式を用いた推論
数理論理学においては,論理式に対して真偽による解釈を与えることで,意味の世界を記号として扱います. これにより,推論を記号の操作として扱う論理体系が構築されました. しかし,そうした論理体系は現実世界の推論を表現するには十分でないことが知られています. 例えば,推論は現実には不確実性を持つことがあるため,その正しさを真と偽の2値で表現することは十分ではありません. そこで,対象とする現実的な問題に即した形で不確実性と既存の論理体系を統合する研究を行っています.
不確実推論に基づく仮説の意味論と仮説管理の支援手法 [6-1]
歴史学における仮説は,不確実な推論の積み重ねにより導出され,統計的に正しさを計測できないことが多いとされています. このような仮説は矛盾を起こすことがあり,矛盾は取り除かれる必要があります.そこで,仮説を導出した不確実推論の積み重ねを, 有向非巡回グラフを用いて表現するための意味論 (Reasoning Webモデル) を構築し, その意味論に基づいて,仮説から矛盾を取り除く手続きなど,人間が行う仮説管理を計算機によって支援する手法を構築しました.
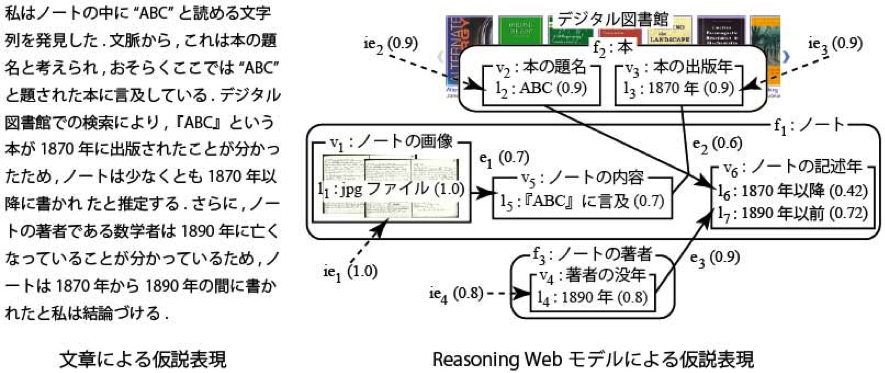
不確実性を伴う人間の推論の論理と確率推論の統合 [6-2]
不確実推論を計算機上で行うものとしてよく知られているBayesian Networkでは,条件付き確率表が必要です.しかし,訓練データが不十分な場合には条件付き確率表の獲得が困難です.そこで,条件付き確率表の代わりに確実性スコア(Certainty Score)を付加した確定節からなる論理プログラムを用いて人間の行う不確実推論を表現する手法を提案しました.また,確定節に与えた確実性スコアの計算によってBayesian Networkにおける確率伝播アルゴリズム(Belief Propagation Algorithm)と同等の振る舞いを表現可能であることを示しました.
節論理のグラフィカルモデル
節論理とは論理積標準形で表現された論理式を扱う論理体系であり,古くから研究されています.一方,グラフィカルモデルは離散構造を表現する一つの手段であり,ベイジアンネットワークやマルコフネットワークなどに代表されます.近年,論理における性質をグラフィカルモデルと対応づける研究が注目されていますが,既存の研究では論理の推論プロセスを十分に把握できているとは言えません.本研究では,節に現れる各原子式の,節に対する寄与率の違いに注目し,論理とグラフィカルモデルに関する研究に一つのフレームワークを提供します.

関係する論文
- [6-1] Ikeda, M., Nishino, M., Doi, K., Yamamoto, A., Hayashi, S. : Semantics of a graphical model for representing hypotheses and a system supporting management of hypotheses, Proceedings of the Fifth International Conference on Knowledge, Information and Creativity Support Systems (KICSS2010), 159-166, 2010.
- [6-2] Masaaki Nishino, Madori Ikeda, Akihiro Yamamoto : Integrating Probabilistic Reasoning and Logic for Expressing Human Inference with Uncertainty, 1st International Workshop on Advanced Methodologies for Bayesian Networks (AMBN 2010), 2010.
計算論的学習と数学
代数学においては,多項式環イデアルが有限基底性を持つことはよく知られていますが,この事実は正データからの極限同定による形式言語の学習可能性の特別な場合であることが明らかになっています.そこで,学習可能性の方が有限基底性よりも詳細な条件分析が行われていることから,学習可能性の条件を基準にして,抽象代数の備えるべき性質を分類しました.その発展として,極限同定における学習の複雑さの理論を用いて,従来よりも大きな超限順序数に意味を与えることに成功しました.さらに,代数学ではあまり考察の対象とはなっていませんが,形式言語の学習ではよく考察の対象となっている「有界集合和」を,多項式環イデアルに適用し,その性質を明らかにする研究も行なっています.
(研究プロジェクト: 学術振興会基盤研究(A))
関係する論文
- [7-1] de Brecht, M., Kobayashi, M., Tokunaga, H., Yamamoto, A. : Inferability of Closed Set Systems From Positive Data, New Frontiers in Artificial Intelligence (Lecture Notes in Artificial Intelligence 4384), Springer, 265-275, 2007.
- [7-2] de Brecht, M, Yamamoto, A : Mind change complexity of inferring unbounded unions of restricted pattern languages from positive data, Theoretical Computer Science, 411(7-9), 976-985 , 2010.
- [7-3] de Brecht, M, Yamamoto, A : Topological properties of concept spaces (full version), Information and Computation, 208(4), 327-340, 2010.
- [7-4] Kameda, Y., Tokunaga, H. , Yamamoto, A. : Learning Bounded Unions of Noetherian Closed Set Systems Via Characteristic Sets, Proc. ICGI 2008, LNAI 5278, 98-110, 2008.
- [7-5] Kameda, Y., Yamamoto, A.: Mining Closed Weighted Itemsets for Numerical Transaction Databases, Proc. of JSAI-isAI 2011 Workshop ALSIP, 197-210, 2011.
計算困難な問題に対するアルゴリズムの研究
(可算な)集合、順列、グラフなどの離散的な対象の上の最適化問題は、その多くがNP困難やさらに難しい問題クラスに属すことが過去の研究で明らかにされています。 大学の一般的な講義における「計算量理論」では、Cook-Levinの定理を代表とするNP完全性の理論に基づいて問題の難しさを議論します。この文脈では、「入力サイズ」に対して多項式時間で動作するチューリング機械の存在を持てば「容易な問題」と定義され、NP完全問題はP = NPでない限り「容易ではない問題」と分類されます。 そのような問題へのアプローチとして、パラメータ化アルゴリズム、指数時間厳密アルゴリズム、近似アルゴリズムなどの代表的な手法が知られています。
当研究室では、伝統的な問題だけに限らず、機械学習やデータマイニングなどの研究中に生じる困難な問題に対し、これらの理論的なアプローチに加え、SATや整数計画法などの高速なソルバを用いた解法の研究も行なっています。
パラメータ化アルゴリズム・パラメータ化計算量理論
パラメータ化計算量理論では、問題に対して「入力サイズ」を2次元的に捉え、「入力サイズ」と「パラメータ」のふたつの値を考えます。 前述の通り、P = NPでない限りNP困難問題を解く「入力サイズ」に関する多項式時間アルゴリズムは存在しないが、ふたつの値をを考慮するとこで新たな計算量理論(パラメータ化計算量理論)が構築されます。 例えば、入力サイズnとパラメータkに対し、O(2kn) 時間で動作するアルゴリズムは、「入力サイズ + パラメータ」に関する多項式時間アルゴリズムではないが、パラメータkが小さい時に、高速に動作することが期待できます。 このような計算時間のアルゴリズムをもつ問題を固定パラメータ容易と呼び、古典的な計算量理論ではあまり扱って来なかったNP困難な問題に対する「容易さ」の研究を行なわれています。
指数時間厳密アルゴリズム
「この問題は指数時間かかるから解けない」という言説を見かけることがありますが、本当にそうでしょうか? 伝統的な計算量理論における「容易な」問題は多項式時間で動作する問題であり、入力サイズnに関してO(n10) 時間で動作するアルゴリズムしか知られていない場合でも容易な問題です。 一方で、O(1.01n) 時間で動作するアルゴリズムが知られていない問題は「解けない」問題なわけですが、現実的に動作する入力サイズの範囲で考えれば、後者の方が高速なアルゴリズムです。 指数時間厳密アルゴリズムの研究は、指数時間で動作するものの、問題の構造がどれだけ小さい指数関数のアルゴリズムを可能にするかを探索します。
近似アルゴリズム
上ふたつのアプローチが「厳密解法」、つまり最適解を求める解法であるのに対し、近似アルゴリズムの研究ではある程度解の質を妥協することで高速なアルゴリズムの設計を目指します。 ただし、ここでいう「妥協」とは理論的に保証された範囲内でなければなりません。そのため、様々なメタヒューリスティックスなどの手法とは異なります。
関係する論文
- [8-1] 久保田稜,小島健介,小林靖明,山本章博:可換マッチング問題の固定パラメーター容易性に関する研究 .人工知能学会,第112回人工知能基本問題研究会, 2020.
- [8-2] Yasuaki Kobayashi, Kensuke Kojima, Norihide Matsubara, Taiga Sone, Akihiro Yamamoto: Algorithms and hardness results for the maximum balanced connected subgraph problem. COCOA 2019.
- [8-3] Yasuaki Kobayashi, Koki Suetsugu, Hideki Tsuiki, Ryuhei Uehara: On the complexity of lattice puzzles. ISAAC 2019.
- [8-4] Eto Hiroshi, Tesshu Hanaka, Yasuaki Kobayashi, Yusuke Kobayashi: Parameterized Algorithmis for Maximum Cut with Connectivity Constraints. IPEC 2019.
- [8-5] Yasuaki Kobayashi, Yusuke Kobayashi, Shuichi Miyazaki, Suguru Tamaki: An Improved Fixed-Parameter Algorithm for Max-Cut Parameterized by Crossing Number. IWOCA 2019.
- [8-6] 小林靖明,曽根大雅,土中哲秀:グラフの2等分割問題に対するアルゴリズムと計算複雑性.情報処理学会 第175回アルゴリズム研究会, 2019.
- [8-7] Eunpyeong Hong, Yasuaki Kobayashi, Akihiro Yamamoto: Improved Methods for Computing Distances between Unordered Trees Using Integer Programming. COCOA 2017.
- [8-8] Masaaki Nishino, Kei Amii, Akihiro Yamamoto: On the Sizes of Decision Diagrams Representing the Set of All Parse Trees of a Context-free Grammar. AMBN 2017.